- Registration form
- Data
- Python and MATLAB example submission and scoring code
- Submission instructions and form
- Leaderboard, results, and papers
- Public discussion forum
- Rules and deadlines
- Current and general FAQs
- About
Digitization and Classification of ECG Images: The George B. Moody PhysioNet Challenge 2024
Summary
The George B. Moody PhysioNet Challenges are annual competitions that invite participants to develop automated approaches for addressing important physiological and clinical problems. The 2024 Challenge invites teams to develop algorithms for digitizing and classifying electrocardiograms (ECGs) captured from images or paper printouts. Despite the recent advances in digital ECG devices, physical or paper ECGs remain common, especially in the Global South. These physical ECGs document the history and diversity of cardiovascular diseases (CVDs), and algorithms that can digitize and classify these images have the potential to improve our understanding and treatment of CVDs, especially for underrepresented and underserved populations.
Announcements
-
September 20, 2024: We have released (and updated) the results of the 2024 Challenge. Congratulations to the winners! Please see the announcement for more details.
-
August 19, 2024: We have extended the official phase deadline to 23:59 GMT on August 21, 2024. Please see the deadlines for the updated deadlines.
-
July 9, 2024: The PhysioNet Challenges spent several days last month at Data Science Africa 2024. The DSAIL at DeKUT helped us to run a hackathon over 4 days with more than 50 attendees, including some that we will win a prize from the IEEE SPS at CinC 2024. Please see this announcement for more information about our trip to DSA.
-
June 14, 2024: Abstract decisions for CinC 2024 have been announced, and the official scoring system is open with a new validation data set that includes images of real paper ECGs. Please submit entries early and often; although you have 10 entries in the scoring system, we may limit each team to one request or deprioritize additional entries from a team in the final week because of the large numbers of entries that we receive in the final days of the Challenge, and because teams that enter earlier tend to perform better!
-
June 6, 2024: We have just completed a 3-day workshop at this year’s annual DSA meeting in Nyeri, Kenya. As part of this capacity-building initiative, we provided another working solution to the ECG image classification task. The code for this can be found here; see also here. The Challenge teams are welcome to use any part of this code in their entry, but we strongly suggest trying other approaches as well. In particular, we deliberately under-designed the model, which does not attempt to digitize the data for classification. We have posted this only to provide a working example, and not as a high bar to beat.
-
May 24, 2024: The official phase of the George B. Moody PhysioNet Challenge 2024 has begun! We have made many updates to make the Challenge more accessible and more realistic. Please see our announcement on the Challenge forum for more details and submit your entries in the coming days.
-
March 15, 2024: We are delighted to announce that the George B. Moody PhysioNet Challenges are partnering with Data Science Africa (DSA) and the IEEE Signal Processing Society’s Challenges and Data Collections Committee (CDCC). The IEEE CDCC is supporting this year’s Challenge with additional cash prizes for participating teams from Africa, and the Challenge organizers will be running a workshop at this year’s annual DSA meeting in Kenya at this year’s annual DSA meeting in Kenya from June 2-5, 2024. Please note that we are also accepting (and scoring) entries, and there are two deadlines coming up:
April 8, 2024April 10, 2024 to submit a preliminary entry to the Challenge and April 15, 2024 to submit a (placeholder) abstract to CinC. -
February 29, 2024: We are now accepting unofficial phase submissions for the 2024 Challenge. Please read the submissions instructions, double check your code, and submit your code when ready.
-
January 25, 2024: The NIH-funded George B. Moody PhysioNet Challenge 2024 is now open! Please read this website for details and share questions and comments on Challenge forum. This year’s Challenge is generously sponsored by MathWorks and AWS.
-
January 11, 2024: The NIH-funded George B. Moody PhysioNet Challenge 2024 will open soon! Please stay tuned for more information.
Introduction
The electrocardiogram (ECG) is an essential pre-screening tool for cardiovascular diseases (CVDs). Non-invasive and painless, the ECG measures the electrical activity of the heart. In 1895, Willem Einthoven invented the first practical ECG device, culminating with the 1924 Nobel Prize in Physiology or Medicine. In 1927, General Electric introduced portable ECG devices, and by 1948, ECG devices could print ECG waveforms on paper. More recently, researchers have developed algorithmic approaches to interpreting ECG waveforms, and many companies have introduced digital ECG devices that record digital representations of the ECG waveforms. These and other developments have served to improve the accessibility of ECG-based diagnosis of CVDs.
However, while digital ECG-based approaches have the potential to improve access to ECG-based diagnoses and cardiac care, physical or paper ECG representations have been a mainstay of cardiac care for nearly a century, and they remain common in much of the world, particularly in the Global South. While an increasing proportion of the estimated 100 to 300 million ECGs that are recorded each year are now in digital formats, there are likely billions of paper ECGs around the world, particularly in the Global South1,2,3. This legacy contains the variability and evolution of CVDs across demographics, geography, and time. Moreover, walled-garden proprietary systems artificially inflate access barriers to processing data. Therefore, the digitization of ECGs and access to low-cost analyses of ECGs is critical for capturing the diversity of representations of ECG data, and therefore the global accessibility of cardiac care.
The George B. Moody PhysioNet Challenge 2024 provides an opportunity to advance the field of ECG-based diagnosis by inviting teams to digitize and classify ECGs captured from images or paper printouts.
Objective
For the 2024 Challenge, we ask participants to design and implement open-source algorithms that can digitize the ECG and/or classify physical ECGs. The Challenge has two separate tasks:
- Digitize the ECGs, i.e., turn images of ECGs (scanned from paper) into waveforms (time-series data) representing the same ECGs;
- Classify the ECGs (either from the image, or from the converted time-series data that you extract from the image).
There are two separate prizes, and you may enter either part or both parts of the Challenge. The winners of each of the two parts of the Challenge will be the teams whose algorithms achieve the best performance on the hidden test set.
Data
The Challenge data are from various sources, including public and private databases of ECG waveforms, ECG images, and/or ECG-based diagnoses or classes. The below images are examples of ECG image.
The below image is a synthetic image that was generated from an ECG waveform. This image does not include distortions, creases, shadows, blurred or faded ink, or other artifacts that obscure the ECG waveforms in paper ECGs:
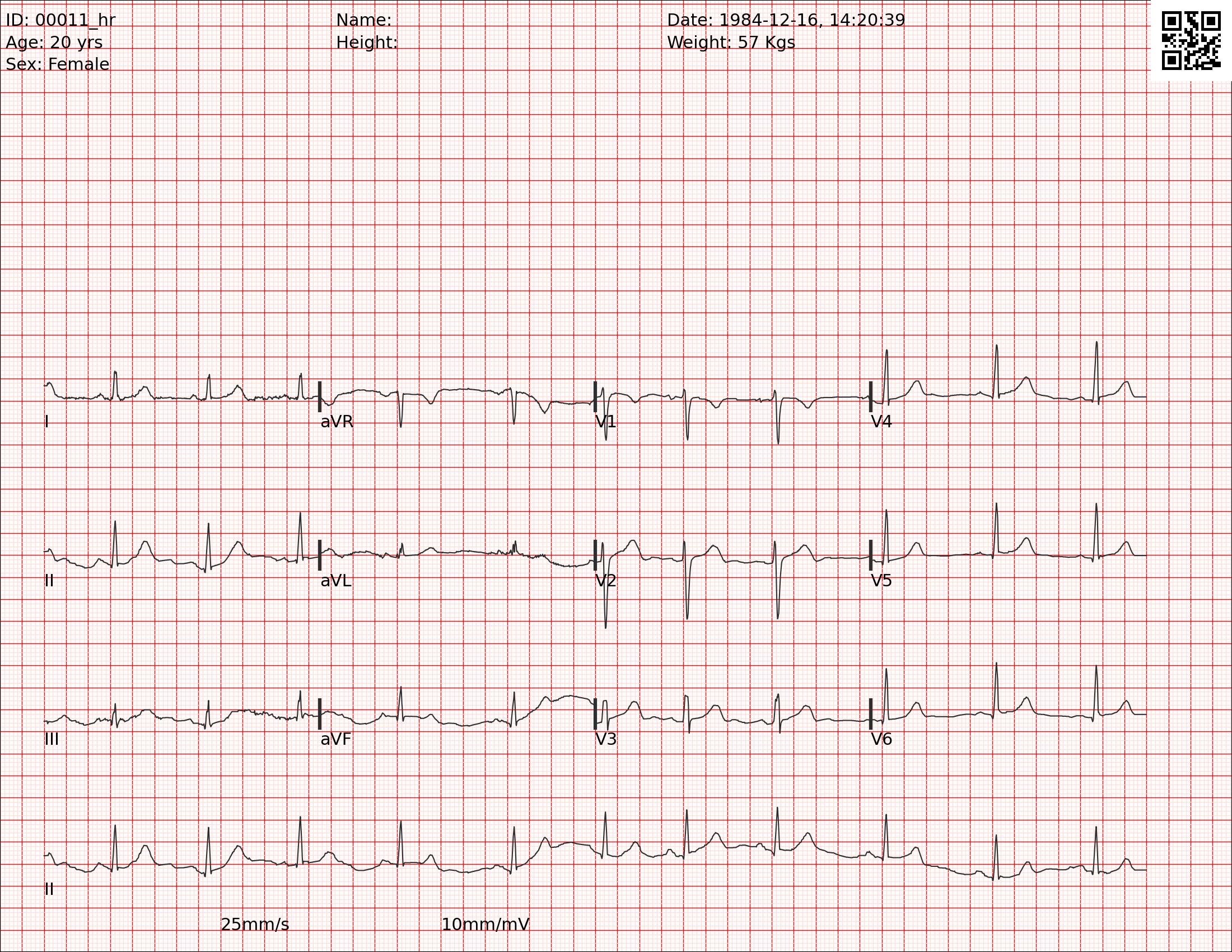
The below image is also a synthetic image that was generated from another ECG waveform, but it includes various distortions that resemble the artifacts in paper ECGs:
The below image is a real image that was generated from a photograph or a scan of a paper ECG and includes various artifacts as well as redacted information:
Your code should learn from, and must be able to digitize and/or classify, a diversity of ECG images. The above images are only a few examples of the diverse synthetic and real ECG images that we may use for the Challenge.
The goal is to digitize the ECG image, i.e., to extract the ECG waveform from the ECG image and reconstruct the WFDB header and signal files, and/or to classify the ECG image.
Data Formats
Each ECG recording will include a WFDB header file, a WFDB signal file, and/or one or more ECG image files.
The WFDB header file describes the ECG recording, including the sampling frequency, signal length, signal resolution, and signal names of the channels in the ECG waveform; initial and checksum values for the channels; and classes and available demographic information. The public training set provides all of this information when available. The private validation and test sets contain the sampling frequency, signal resolution, and signal names; they do not provide the initial and checksum values or the classes or (sometimes) demographic information. Your algorithm should be robust to added and missing information (such as age, date, automated diagnosis, etc.) to reflect the real world. Our test data is designed to be complex enough to reflect this type of missingness.
| Training set | Validation set | Test set | |
|---|---|---|---|
| WFDB header file | Present (full) | Present (partial) | Present (partial) |
| WFDB signal file | Present | Absent | Absent |
| Image file | Present | Present | Present |
For example, the PTB-XL dataset includes the WFDB header file 00001_hr.hea and the WFDB signal file 00001_hr.dat for the record 00001_hr:
00001_hr 12 100 1000
00001_hr.dat 16 1000.0(0)/mV 16 0 -119 1508 0 I
00001_hr.dat 16 1000.0(0)/mV 16 0 -55 723 0 II
00001_hr.dat 16 1000.0(0)/mV 16 0 64 64758 0 III
00001_hr.dat 16 1000.0(0)/mV 16 0 86 64423 0 AVR
00001_hr.dat 16 1000.0(0)/mV 16 0 -91 1211 0 AVL
00001_hr.dat 16 1000.0(0)/mV 16 0 4 7 0 AVF
00001_hr.dat 16 1000.0(0)/mV 16 0 -69 63827 0 V1
00001_hr.dat 16 1000.0(0)/mV 16 0 -31 6999 0 V2
00001_hr.dat 16 1000.0(0)/mV 16 0 0 63759 0 V3
00001_hr.dat 16 1000.0(0)/mV 16 0 -26 61447 0 V4
00001_hr.dat 16 1000.0(0)/mV 16 0 -39 64979 0 V5
00001_hr.dat 16 1000.0(0)/mV 16 0 -79 832 0 V6
The provided scripts expand the WFDB header file 00001_hr.hea to include the provided demographic and diagnostic information to create a synthetic ECG image file 00001_hr-0.png for the record 00001_hr. The labels in the Labels: field provide the label or labels for the data , and the images are synthetic ECG images:
{kind=link}
00001_hr 12 100 1000 09:17:34 09/11/1984
00001_hr.dat 16 1000.0(0)/mV 16 0 -119 1508 0 I
00001_hr.dat 16 1000.0(0)/mV 16 0 -55 723 0 II
00001_hr.dat 16 1000.0(0)/mV 16 0 64 64758 0 III
00001_hr.dat 16 1000.0(0)/mV 16 0 86 64423 0 AVR
00001_hr.dat 16 1000.0(0)/mV 16 0 -91 1211 0 AVL
00001_hr.dat 16 1000.0(0)/mV 16 0 4 7 0 AVF
00001_hr.dat 16 1000.0(0)/mV 16 0 -69 63827 0 V1
00001_hr.dat 16 1000.0(0)/mV 16 0 -31 6999 0 V2
00001_hr.dat 16 1000.0(0)/mV 16 0 0 63759 0 V3
00001_hr.dat 16 1000.0(0)/mV 16 0 -26 61447 0 V4
00001_hr.dat 16 1000.0(0)/mV 16 0 -39 64979 0 V5
00001_hr.dat 16 1000.0(0)/mV 16 0 -79 832 0 V6
# Age: 56
# Sex: Female
# Height: Unknown
# Weight: 63
# Labels: NORM
# Image: 00001_hr-0.png
In the training set, these files will be available to your code. In the validation and test sets, the WFDB header file would be abbreviated to remove most information about the waveform, demographics, and labels, and the WFDB signal file would be removed to remove the waveform, but the image file would still be available:
00001_hr 12 100 1000
00001_hr.dat 16 1000.0(0)/mV 16 0 I
00001_hr.dat 16 1000.0(0)/mV 16 0 II
00001_hr.dat 16 1000.0(0)/mV 16 0 III
00001_hr.dat 16 1000.0(0)/mV 16 0 AVR
00001_hr.dat 16 1000.0(0)/mV 16 0 AVL
00001_hr.dat 16 1000.0(0)/mV 16 0 AVF
00001_hr.dat 16 1000.0(0)/mV 16 0 V1
00001_hr.dat 16 1000.0(0)/mV 16 0 V2
00001_hr.dat 16 1000.0(0)/mV 16 0 V3
00001_hr.dat 16 1000.0(0)/mV 16 0 V4
00001_hr.dat 16 1000.0(0)/mV 16 0 V5
00001_hr.dat 16 1000.0(0)/mV 16 0 V6
# Image: 00001_hr-0.png
Data Labels
The labels for the ECG images belong to the following classes:
- Normal ECG: NORM
- Acute myocardial infarction: Acute MI
- Old myocardial infarction: Old MI
- ST/T changes: STTC
- Conduction disturbances: CD
- Hypertrophy: HYP
- Premature atrial complex: PAC
- Premature ventricular complex: PVC
- Atrial fibrillation or atrial flutter: AFIB/AFL
- Tachycardia: TACHY
- Bradycardia: BRADY
The labels are derived from the labels provided with each database and minimally homogenized so that you can training a method on one dataset and perform inference on another dataset without changing your code. For the training set, the labels are given by the labels in the PTB-XL database5, except for the myocardial infraction (MI) class, which we split into acute and old MI classes using the 12SL labels from the PTB-XL+ database 6; the exact details are given in the script for preparing the PTB-XL data for the Challenge. In general, the labels were overread by at least one human expert, but practices vary between and within each database.
Data Processing
Patient information includes available demographic and label information. To protect patient privacy, potential identifiers in the ECG images were redacted, and all ages above 89 years were aggregated into a single category and encoded as “90” for data shared as part of the Challenge.
The synthetic ECG image generator from ECG-Image-Kit allows teams to augment the training set by creating synthetic ECG images from ECG time-series data with various artifacts. Teams can generate these images by including this or other code within their entries and running it as part of their training step. Note that the teams real ECG images have various artifacts due to printing, handling, storage, and scanning, and the synthetic ECG image generator introduces artifacts, such as shifting and rotating the ECG paper, adding creases and other artifacts, changing font sizes and font types, etc., to better capture the realism and diversity of real-world ECG images.
Data Splits: Training, Validation, and Test Sets
For the training set, we are using the waveforms and labels from the PTB-XL dataset5, 6, which has 21,799 12-lead ECG recordings. The teams may augment these data these additional datasets, including (but not restricted to) the following sources:
- PTB-XL Dataset5: 21,799 12-lead ECG recordings
- The PhysioNet Challenge 2021 Datasets7: 88,253 12-lead ECG recordings
- The CODE-15% dataset8: 345,779 12-lead ECG recordings
If you use these or other data as part of your method, then please cite them appropriately to clarify your method and attribute the data contributors.
For the validation and test sets, we are using waveforms, images, and labels from additional databases. The held-out validation and test sets will have actual scans or photographs of paper ECGs, and they will contain the same or a subset of the classes as the public training set.
The training set is public, but the validation and test sets are hidden. We will evaluate your models on the validation set during the unofficial and official phases of the Challenge, and we will evaluate at most one model from each team on the test set after the official phase of the Challenge.
Loading the Data
Patient files are in WFDB format. These files can be opened in either MATLAB or Python. We provide example code for loading and processing the data.
Accessing the Data
The training set can be downloaded from PhysioNet.org and PhysioNet.org. You can download the data by clicking on the link or running the wget command on the page. You can prepare the data for the Challenge by following the following steps:
-
Download (and unzip) the PTB-XL dataset and PTB-XL+ dataset. These instructions use
ptb-xlas the folder name that contains the data for these commands (the full folder name for the PTB-XL dataset is currentlyptb-xl-a-large-publicly-available-electrocardiography-dataset-1.0.3, and the full folder name for the PTB-XL dataset is currentlyptb-xl-a-comprehensive-electrocardiographic-feature-dataset-1.0.1), but you can replace it with the absolute or relative path on your machine. -
Add information from various spreadsheets from the PTB-XL dataset to the WFDB header files:
python prepare_ptbxl_data.py \ -i ptb-xl/records500/00000 \ -pd ptb-xl/ptbxl_database.csv \ -pm ptb-xl/scp_statements.csv \ -sd ptb-xl/12sl_statements.csv \ -sm ptb-xl/12slv23ToSNOMED.csv \ -o ptb-xl/records500/00000 -
Generate synthetic ECG images on the dataset:
python gen_ecg_images_from_data_batch.py \ -i ptb-xl/records500/00000 \ -o ptb-xl/records500/00000 \ --print_header \ --store_config 2 -
Add the file locations and other information for the synthetic ECG images to the WFDB header files. (The expected image filenames for record
12345are of the form12345-0.png,12345-1.png, etc., which should be in the same folder.) You can use theptb-xl/records500/00000folder for thetrain_modelstep:python prepare_image_data.py \ -i ptb-xl/records500/00000 \ -o ptb-xl/records500/00000 -
Remove the waveforms, certain information about the waveforms, and the demographics and classes to create a version of the data for inference. You can use the
ptb-xl/records500_hidden/00000folder for therun_modelstep, but it would be better to repeat the above steps on a new subset of the data that you will not use to train your model:python gen_ecg_images_from_data_batch.py \ -i ptb-xl/records500/00000 \ -o ptb-xl/records500_hidden/00000 \ --print_header \ --mask_unplotted_samples python prepare_image_data.py \ -i ptb-xl/records500_hidden/00000 \ -o ptb-xl/records500_hidden/00000 python remove_hidden_data.py \ -i ptb-xl/records500_hidden/00000 \ -o ptb-xl/records500_hidden/00000 \ --include_images
Registering for the Challenge and Conditions of Participation
To participate in the Challenge, register your team by providing the full names, affiliations, and official email addresses of your entire team before you submit your algorithm. The details of all authors must be exactly the same as the details in your abstract submission to Computing in Cardiology. You may update your author list by completing this form again (read the form for details), but changes to your authors must not contravene the rules of the Challenge.
Algorithms
For each ECG recording, your algorithm must digitize ECG image, i.e., reconstruct the ECG waveform from the ECG image, and/or to classify the ECG image. Teams can choose to complete either task or both tasks.
We implemented example algorithms in MATLAB and Python. Other implementation languages will be considered upon request. The code repositories contain details for the examples and other helpful scripts and functions. These examples were not designed to perform well but to provide minimal working examples of how to work with the data for the Challenge task.
Given the computational complexity of generating and training on large numbers of synthetic ECG images, we are asking you to submit your complete code base, including your training code, along with a pre-trained model. We will run your training code on a small subset of the training set to check it for errors, but we will score your pre-trained model on the validation set. At the end of the Challenge, we will re-run your training code on the full training set and score the resulting model on the test set.
Submitting your Algorithm
Please use the above example code as templates for your submissions.
Please see the submission instructions for detailed information about how to submit a successful Challenge entry, double check your code (we cannot debug your code for you), and submit your algorithm after we begin accepting code submissions. We will provide feedback on your entry as soon as possible, so please wait at least 72 hours before contacting us about the status of your entry.
Please note that you remain the owners of any code that you submit, and we encourage you to use an open-source license.
Scoring
The evaluation metric for the digitization task is the signal-noise ratio (SNR) of the reconstructed signal, and the evaluation metric for the classification task is the macro F-measure. Higher values of both evaluation metrics are better. The team with the highest SNR wins the digitization task, and the team with the highest macro F-measure wins the classification tasks.
These metrics are implemented in the evaluate_model script. We invite feedback about these metrics.
Overview of rules
There are two phases for the Challenge: an unofficial phase and an official phase. The unofficial phase of the Challenge allows us to introduce and “beta test” the data, scores, and submission system before the official phase of the Challenge. Participation in the unofficial phase is mandatory for participating in the official phase of the Challenge because it helps us to improve the official phase.
Entrants may have an overall total of up to 15 scored entries over both the unofficial and official phases of the competition (see the below table). We will evaluate these entries on the validation set during the unofficial and official phases, and we will evaluate at most on successful official phase entry from each team on the test set after the official phase. All deadlines occur at 11:59pm GMT on the dates mentioned below, and all dates are during 2024 unless indicated otherwise. If you do not know the difference between GMT and your local time, then find it out before the deadline!
Please submit your entries early to ensure that you have the most chances for success. If you wait until the last few days to submit your entries, then you may not receive feedback before the submission deadline, and you may be unable to resubmit your entries if there are unexpected errors or issues with your submissions. Every year, several teams wait until the last few days to submit their first entry and are unable to debug their work before the deadline.
Timing and priority of entries
Although we score on a first-come-first-serve basis, please note that if you submit more than one entry in a 24-hour period, your second entry may be deprioritized compared to other teams’ first entries. If you submit more than one entry in the final 24 hours before the Challenge deadline, then we may be unable to provide feedback or a score for more than one of your entries. It is unlikely that we will be able to debug any code in the final days of the Challenge.
For these reasons, we strongly suggest that you start submitting entries at least 5 days before the unofficial deadline and 10 days before the official deadline. We have found that the earlier teams enter the Challenge, the better they do because they have time to digest feedback and performance. We therefore suggest entering your submissions many weeks before the deadline to give yourself the best chance for success.
Key dates/deadlines
| Start | End | Submissions | |
|---|---|---|---|
| Unofficial phase | 25 January 2024 | 10 April 2024 | 1-5 scored entries (*) |
| Hiatus | 11 April 2024 | 23 May 2024 | N/A |
| Abstract deadline | 15 April 2024 | 15 April 2024 | 1 abstract |
| Official phase | 24 May 2024 | 21 August 2024 | 1-10 scored entries (*) |
| Abstract decisions released | Mid-June 2024 | Mid-June 2024 | N/A |
| Wild card entry date | 6 August 2024 | 6 August 2024 | N/A |
| Hiatus | 22 August 2024 | 7 September 2024 | N/A |
| Deadline to choose algorithm for test data | 27 August 2024 | 27 August 2024 | N/A |
| Preprint deadline | 28 August 2024 | 28 August 2024 | One 4-page paper (**) |
| Conference | 8 September 2024 | 11 September 2024 | 1 presentation (**) |
| Final scores released | Mid-September 2024 | Mid-September 2024 | N/A |
| Final paper deadline | 1 October 2024 | 1 October 2024 | One 4-page paper (***) |
(* Entries that fail to score do not count against limits.)
(** Must include preliminary scores.)
(*** Must include final scores, your ranking in the Challenge, and any updates to your work as a result of feedback after presenting at CinC. This final paper deadline is earlier than the deadline given by CinC so that we can check these details.)
To be eligible for the open-source award, you must do all the following:
- Register for the Challenge here.
- Submit at least one open-source entry that can be scored during the unofficial phase.
- Submit an abstract to CinC by the abstract submission deadline. Include your team name and score from the unofficial phase in your abstract. Please select “PhysioNet/CinC Challenge” as the topic of your abstract so that it can be identified easily by the abstract review committee. Please read “Advice on Writing an Abstract” for important information on writing a successful abstract.
- Submit at least one open-source entry that can be scored during the official phase.
- Submit a full 4-page paper on your work to CinC by the above preprint deadline.
- One of your team members must attend CinC 2024 to present your work either orally or as a poster (depending on your abstract acceptance). If you have a poster, then you must stand by it to defend your work. No-shows (oral or poster) will be disqualified. One of your team members must also attend the closing ceremony to collect your prize. No substitutes will be allowed. If the conference permits remote attendance, then you will be eligible for ranking if you attend remotely (and fulfill the other required criteria), but teams must attend in person for prize eligibility.
- Submit a full 4-page paper on your work to CinC by the above final paper deadline. Please note that we expect the abstract to change significantly both in terms of results and methods. You may also update your title with the caveat that it must not be substantially similar to the title of the competition or contain the words “physionet,” “challenge,” or “competition.”
You must not submit an analysis of this year’s Challenge data to other conferences or journals until after CinC 2024 so that we can discuss the Challenge in a single forum. If we discover evidence that you have submitted elsewhere before the end of CinC 2024, then you will be disqualified and de-ranked on the website, banned from future Challenges, and the journal/conference will be contacted to request your article be withdrawn for contravention of the terms of use.
There are many reasons for this policy: (1) we do not release results on the test data before the end of CinC, and only reporting results on the training data increases the likelihood of overfitting and is not comparable to the official results on the test data, and (2) attempting to publish on the Challenge data before the Challengers present their results is unprofessional and comes across as a territorial grab. This requirement stands even if your abstract is rejected, but you may continue to enter the competition and receive scores. (However, unless you are accepted into the conference at a later date as a “wild card” entry, you will not be eligible to win a prize.) Of course, any publicly available data that was available before the Challenge is exempted from this condition, but any of the novelty of the Challenge (the Challenge design, the Challenge data that you downloaded from this page because it was processed for the Challenge, the scoring function, etc.) is not exempted.
After the Challenge is over and the final scores have been posted (in late September), everyone may then submit their work to a journal or another conference.
Wild Card Entries
If your abstract is rejected or if you otherwise failed to qualify during the unofficial period, then there is still a chance to present as CinC and win the Challenge. A “wild card” entry has been reserved for a high-scoring entry from a team that was unable to submit an accepted abstract to CinC by the original abstract submission deadline. A successful entry must be submitted by the wild card entry deadline. We will contact eligible teams and ask them to submit an abstract. The abstract will still be reviewed as thoroughly as any other abstract accepted for the conference. See Advice on Writing an Abstract.
Advice on Writing an Abstract
To improve your chances of having your abstract accepted, we offer the following advice:
- Ensure that all of your authors agree on your abstract, and be sure that all of the author details match your registration information, including email addresses.
- Stick to the word limit and deadline on the conference website. Include time for errors, internet outages, etc.
- Select “PhysioNet/CinC Challenge” as the submission topic so it can be identified easily by the abstract review committee. However, do not include the words “PhysioNet” or “PhysioNet/CinC” or “Challenge” in the title because this creates confusion with the hundreds of other articles and the main descriptor of the Challenge.
- Your title, abstract and author list (collaborators) can be modified in September when you submit the final paper.
- While your work is bound to change, the quality of your abstract is a good indicator of the final quality of your work. We suggest you spell check, write in full sentences, and be specific about your approaches. Include your method’s cross validated training performance (using the Challenge metrics) and your score provided by the Challenge submission system. If you omit or inflate this latter score, then your abstract will be rejected.
- Do not be embarrassed by any low scores. We do not expect high scores at this stage. We are focused on the thoughtfulness of the approach and quality of the abstract.
- If you are unable to receive a score during the unofficial phase, then you can still submit, but the work should be of very high quality and you should include the cross validation results of your algorithm on the training set.
You will be notified if your abstract has been accepted by email from CinC in June. You may not enter more than one abstract describing your work in the Challenge. We know you may have multiple ideas, and the actual abstract will evolve over the course of the Challenge. More information, particularly on discounts and scholarships, can be found here. We are sorry, but the Challenge Organizers do not have extra funds to enable discounts or funding to attend the conference.
Again, we cannot guarantee that your code will be run in time for the CinC abstract deadline, especially if you submit your code immediately before the deadline. It is much more important to focus on writing a high-quality abstract describing your work and submit this to the conference by abstract deadline. Please follow these instructions here carefully.
Please make sure that all of your team members are authors on your abstract. If you need to add or subtract authors, do this at least a week before the abstract deadline. Asking us to alter your team membership near or after the deadline is going to lead to confusion that could affect your score during review. It is better to be more inclusive on the abstract in terms of authorship, though, and if we find authors have moved between abstracts/teams without permission, then this is likely to lead to disqualification. As noted above, you may change the authors/team members later in the Challenge.
Please make sure that you include your team name, your official score as it appears on the leaderboard, and cross validation results in your abstract using the scoring metrics for this year’s Challenge (especially if you are unable to receive a score or are scoring poorly). The novelty of your approach and the rigor of your research is much more important during the unofficial phase. Please make sure you describe your technique and any novelty very specifically. General statements such as “a 1D CNN was used” are uninformative and will score poorly in review.
The Challenge Organizers have no ability to help with any problems with the abstract submission system. We do not operate it. Please do not email us with issues related to the abstract submission system.
Intellectual Property and Open-Source Licenses
Please note that each team remains the owners of their code and retain the intellectual property (IP) of their code. We encourage the use of open-source licenses for your entries.
Entries with non open-source licenses will be scored but not ranked in the official competition. All scores will be made public. At the end of the competition, all entries will be posted publicly, and therefore automatically mirrored on several sites around the world. We have no control over these sites, so we cannot remove your code even on request. Code which the organizers deem to be functional will be made publicly available after the end of the Challenge. You can request to withdraw from the Challenge, so that your entry’s performance is no longer listed in the official leaderboard, up until a week before the end of the official phase. However, the Organizers reserve the right to publish any submitted open-source code after the official phase is over. The Organizers also retain the right to use a copy of submitted code for non-commercial use. This allows us to re-score if definitions change and validate any claims made by competitors.
If no license is specified in your submission, then the license given in the example code will be added to your entry, i.e., we will assume that you have released your code under the BSD 3-Clause license.
Rules on Competing in Teams / Collaboration
To maintain the scientific impact of the Challenges, it is important that all Challengers contribute truly independent ideas. For this reason, we impose the following rules on team composition/collaboration:
- Multiple teams from a single entity (such as a company, university, or university department) are allowed as long as the teams are truly independent and do not share team members (at any point), code, or any ideas. Multiple teams from the same research group or company unit are not allowed because of the difficulty of maintaining independence in those situations. If there is any question on independence, the teams will be required to supply an official letter from the company that indicates that the teams do not interact at any point (socially or professionally) and work in separate facilities, as well as the location of those facilities.
- You can join an existing team before the abstract deadline as long as you have not belonged to another team or communicated with another team about the current Challenge. You may update your author list by completing this form again (check the “Update team members” box on the form), but changes to your authors must not contravene the rules of the Challenge.
- You may use public code from another team if they posted it before the competition.
- You may not make your Challenge code publicly available during the Challenge or use any code from another Challenger that was shared, intentionally or not, during the course of the Challenge.
- You may not publicly post information describing your methods (blog, vlog, code, preprint, presentation, talk, etc.) or give a talk outside your own research group at any point during the Challenge that reveals the methods you have employed or will employ in the Challenge. Obviously, you can talk about and publish the same methods on other data as long as you don’t indicate that you used or planned to use it for the Challenge.
- You must use the same team name and email address for your team throughout the course of the Challenge. The email address should be the same as the one used to register for the Challenge, and to submit your abstract to CinC. Note that the submitter of the conference article/code does not need to present at the conference or be in any particular location in the author order on the abstract/poster/paper, but they must be a contributing member of the team. If your team uses multiple team names and/or email addresses to enter the Challenge, then please contact the Organizers immediately to avoid disqualification of all team members concerned. Ambiguity will result in disqualification.
- If you participate in the Challenge as part of a class project, then please treat your class as a single team — please use the same team name as other groups in your class, limit the number of submissions from your class to the number allowed for each team, and feel free to present your work within your class. If your class needs more submissions than the Challenge submission limits allow, then please perform cross-validation on the training data to evaluate your work.
If we discover evidence of the contravention of these rules, then you will be ineligible for a prize and your entry publicly marked as possibly associated with another entry. Although we will contact the team(s) in question, time and resources are limited and the Organizers must use their best judgment on the matter in a short period of time. The Organizers’ decision on rule violations will be final.
Similarly, no individual who is affiliated with the same research group, department, or similar organization unit (academic or industry) as one or more of the Organizers of that year’s Challenge researchers may officially participate in the Challenge for that year, even if they do not collaborate with Organizers. If you are uncertain if your shared affiliation disallows you from officially participating, then please contact the Challenge Organizers for clarification. This rule is to prevent concerns about independence or favoritism.
Checking Your Code to Avoid Disqualification
Please note, as we do every year, we will perform some simple tests on your code to ensure it is more usable and reusable. We suggest you also try these similar approaches, including:
- Change the data and/or labels in the training set. Does your code work with missing, unknown, non-physiological values in the data? Does your code work if you change the prevalence rates of the classes or remove one of the classes? (It will probably have a slightly different performance, but that is to be expected.)
- Change the size of the training set. You can extract a subset of the training set or duplicate the training set. Does your code work with a training set that is 15% or 150% of the size of the original training set? (Again, your performance will differ, but the code should still execute.)
- Run your training code on the modified training set. If your training code fails, then your code is too sensitive to the changes in the training set, and you should update your code until it works as expected.
- Score the resulting model on part of the unmodified training set — ideally, data that you did not use to train your model. If your code fails, or if the model trained on the modified training set receives the same scores or almost the same scores as the model trained on the unmodified training set, then your training code didn’ t learn from the training set, and you should update your code until it works as expected.
Again, this is a simplified process, and we may change how we stress test your code in future tests (such as randomizing the labels), so please think about how you can ensure that your code isn’t dependent on a single set of data and labels or a single test for robustness. Of course, you should also try similar steps to check the rest of your code as well.
All of this work is in service of protecting your scientific contributions over the course of the Challenge, and we appreciate, as always, your feedback and help.
Conference Attendance
CinC 2024 will take place from 8-11 September 2024 in Karlsruhe, Germany. You must attend the whole conference to be eligible for prizes. If you send someone in your place who is not a team member or co-author, then you will be disqualified and your abstract will be removed from the proceedings. In particular, it is vital that the presenter (oral or poster) can defend your work and have in-depth knowledge of all decisions made during the development of your algorithm. Due to this year’s challenges, both in-person and remote attendance are allowed, but only in-person attendees are eligible for prize money. If you require a visa to attend the conference, we strongly suggest that you apply as soon as possible. Please contact the local conference organizing committee (not the Challenge Organizers) for any visa sponsorship letters and answer any questions concerning the conference.
To increase engagement from African researchers, the IEEE Signal Processing Society’s Challenges and Data Collections Committee is supporting this year’s Challenge with additional cash prizes for participating teams from Africa. In addition, the organizers will be hosting a workshop on the topic at the annual Data Science Africa meeting in June, in Kenya. Please note that you do not need to attend the DSA meeting in June to enter the Challenge, and you do not need to travel to the final prize ceremony to be eligible for an award (if your team is based in Africa).
Please join us in shaping the future of cardiovascular health!
Hackathon
A hackathon closely related to the Challenge will be held in the building of the Sunday Symposium (see here for directions) on Sunday, September 8 from 11:00am to 6:00pm. A hands-on session to help you get started will occur from 11:00am to 11:30am. Swag (including a USB stick with the Challenge training data and example code) will be available to early attendees.
Attendees need to bring their laptops with WiFi capabilities. Attendees do not need to have entered the hackathon before, and may join existing or new teams. Feel free to look up the most interesting teams in the preprints and email them!
To attend, please sign up here. Space is limited.
Sponsors
This year’s Challenge is generously sponsored by MathWorks, AWS, and the IEEE SPS.
Obtaining Complimentary MATLAB Licenses
MathWorks has generously decided to sponsor this Challenge by providing complimentary licenses to all teams that wish to use MATLAB. Users can apply for a license and learn more about MATLAB support by visiting the PhysioNet Challenge page from MathWorks. If you have questions or need technical support, then please contact MathWorks at studentcompetitions@mathworks.com.
Acknowledgements
Supported by the National Institute of Biomedical Imaging and Bioengineering (NIBIB) under NIH grant R01EB030362.
References
-
Geoffrey H. Tison, Jeffrey Zhang, Francesca N. Delling and Rahul C. Deo. Automated and Interpretable Patient ECG Profiles for Disease Detection, Tracking, and Discovery Circulation: Cardiovascular Quality and Outcomes. 2019;12:e005289, Originally published 5 Sep 2019. Online at: https://doi.org/10.1161/CIRCOUTCOMES.118.005289
-
Sarah Handzel, Retrospective Analysis of ECG Data Supports Cardiologists’ Clinical Judgment, GE HealthCare. 9 Feb 2023. Online at: https://www.gehealthcare.com/insights/article/retrospective-analysis-of-ecg-data-supports-cardiologists’-clinical-judgment
-
Kshama Kodthalu Shivashankara, Deepanshi, Afagh Mehri Shervedani, Matthew A. Reyna, Gari D. Clifford, Reza Sameni (2024). ECG-Image-Kit: a synthetic image generation toolbox to facilitate deep learning-based electrocardiogram digitization. Physiological Measurement. IOP Publishing. Vol 45, 055019, doi: 10.1088/1361-6579/ad4954
-
ECG-Image-Kit: A Toolkit for Synthesis, Analysis, and Digitization of Electrocardiogram Images, January 2024, Online at: https://github.com/alphanumericslab/ecg-image-kit. doi: 10.5281/zenodo.12731152
-
Patrick Wagner, Nils Strodthoff, Ralf-Dieter Bousseljot, Dieter Kreiseler, Fatima I. Lunze, Wojciech Samek and Tobias Schaeffter. PTB-XL: A Large Publicly Available ECG Dataset. Sci Data 7, 154 (2020). Online at: https://doi.org/10.1038/s41597-020-0495-6
-
Nils Strodthoff, Temesgen Mehari, Claudia Nagel, Philip J. Aston, Ashish Sundar, Claus Graff, Jørgen K. Kanters, Wilhelm Haverkamp, Olaf Dössel, Axel Loewe, Markus Bär & Tobias Schaeffter. PTB-XL+, a comprehensive electrocardiographic feature dataset. Sci Data 10, 279 (2023). Online at: https://doi.org/10.1038/s41597-023-02153-8
-
Matthew A. Reyna, Nadi Sadr, Erick A.P. Alday, Annie Gu, Amit J. Shah, Chad Robichaux, Ali Bahrami Rad, Andoni Elola, Salman Seyedi, Sardar Ansari, Hamad Ghanbari, Qiao Li, Ashish Sharma, Gari D. Clifford. Issues in the automated classification of multilead ECGs using heterogeneous labels and populations. Physiol. Meas. 43, 8 (2021), 084001. Online at: https://doi.org/10.1088/1361-6579/ac79fd
-
Antônio H. Ribeiro, Gabriela Paixao, Emilly Lima, Manoel Horta Ribeiro, Marcelo Pinto Filho, Paulo Gomes,
Derick Oliveira Wagner Meira Jr, Thömas Schon, Antonio Luiz Ribeiro. CODE-15%: a large scale annotated dataset of 12-lead ECGs. Zenodo (2021). Online at: https://doi.org/10.5281/zenodo.4916206
This year’s Challenge is generously sponsored by MathWorks, AWS, and the IEEE SPS.
![]()

![]()
Supported by the National Institute of Biomedical Imaging and Bioengineering (NIBIB) under NIH grant number R01EB030362.
© PhysioNet Challenges. Website content licensed under the Creative Commons Attribution 4.0 International Public License.